As a consultant for the past five years, I’ve had the opportunity to run several large data projects for businesses in multiple industries. Usually the request is to help them make better business decisions based on the advanced analytics they will get from bigger, better, faster data. However, once the project starts and business interviews and process mapping begins, the biggest and most immediate improvement almost always comes from updating bad processes, not necessarily the data.
Below I present two projects that were presupposed to be data problems, when in fact they were process problems. They highlight both the challenges internally and what steps needed to be taken to be improved.
Project 1 – Education Industry
In a request for better predictive analytics to indicate cheating in real-time, I uncovered the following process problem:
Multiple people were transforming a dead data set in order to run analytics on it, and then storing it as another dead data set.
What I mean by ‘dead data set’ is that a flat file would come in the doors, four different analytics departments would transform it into a SAS data set they could use, store the SAS data set on the server, and then run analytics to produce ANOTHER SAS data set. These were time-based files, and didn’t include previous periods.
Their problem was multi-faceted:
- The process took too long and couldn’t be put into production for real-time data streams,
- The files produced were extremely disparate, and
- Files weren’t named based on a common protocol, so they were hard to find if you weren’t the one naming the file.
The solution
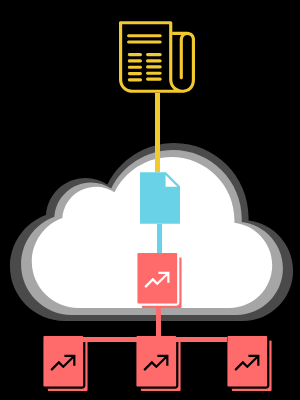
Instead of doing a manual ETL (Extract, Transform, Load) process when the data came in, the files were added to a data lake via automated Load process. A process was added within the data lake to transform the data and combine it for a singular view of all the data. SAS was set up within the data lake environment (instead of locally on individual analyst’s computers), and therefore analysis could be run much faster and across all data. The analysis produced was then saved according to naming protocols so others could access as well.
Not only did the analysts get bigger, badder, and better analysis capabilities, but the time it took to get the analysis completed dropped from a week to hours. Plus, more analysts could spend more time actually running analysis as opposed to doing manual ETL processes. Most importantly, the data was no longer ‘dead’ – it was very much alive and ready for use.
Project 2 – Insurance Industry
A similar request for better predictive analytics came from a large insurance agency. They wanted to better understand the impact of their agents and underwriters, which types of policies were the most profitable, and how much risk they could take on without losing money.
Acting as a BA for project initiation, I had the opportunity to talk with multiple people in all areas of the business, map the applications used, and diagram how the applications fit together. When this was completed, I ended up with a process diagram that was an absolute mess! Everything seemed hacked together in a flow that didn’t make logical sense.
The underlying reason things were this bad was because they created their ‘digital’ process based on the paper process they used before computers. As in, they did all their selling, underwriting, and communications based on the process from 1985: A piece of mail comes into the mail room, it’s opened and sent to someone’s desk, the person writes notes on the piece of paper, the piece of paper is then sent over for review, the piece of paper is approved and sent to the financial department to be issued, and a piece of paper is mailed back to the requestor.
But now they did this same process via Outlook and saved PDF files. Yes, you read that correctly. The PDF files were saved in a repository, and passed around via email.
The solution
They didn’t implement the solution, which was to tear everything down and start fresh. I recommended they use a cloud-based data server with applications for the agents to submit data. The data could then be accessed by underwriters, who could use a simple algorithm to determine risk and assign a score to the record. The data could then be accessed by the financial team to implement the policy and resulting transactions. Only THEN could they start doing analysis on how the risk algorithm score could be optimized.
However, that was too expensive, so they decided to stay the current course and try and do risk analytics off of a small subset of data that had been stored digitally.
Final thoughts
It’s easy for the C-Suite to call down from the executive offices for better predictive analytics, but almost impossible to achieve them without dedicated process improvement. That takes money. BUT, that money will almost be immediately returned in the form of cost efficiencies, whether they’re personnel (ie Janet that is the only one that knows how to run this database), time-based (ie Jeff is the only one that can do that report, and he’s on vacation), or operational (ie we have four people on staff that are constantly fixing legacy systems).
Here are some immediate questions you can ask to determine if it’s a process problem:
- Does it take too long for simple processes to get done?
- Is it hard to find things, like reports or files?
- Do I have a person in my organization that cannot get hit by a bus, or things will completely fall apart?
If you answered yes to one or more of these, you most certainly have a process problem. Fix the process, save money, and get better data and resulting analytics.